Prerequisites
In order to connect Cube to Snowflake, you need to grant certain permissions to the Snowflake role
used by Cube. Cube requires the role to have
USAGE on databases and schemas
and SELECT on tables. An example configuration:- Account/Server URL for Snowflake.
- User name and password or an RSA private key for the Snowflake account. In Cube Cloud, you can authenticate with OIDC workload identity instead — the same role grants apply to the mapped service user.
- Optionally, the warehouse name, the user role, and the database name.
Setup
Manual
Add the following to a.env file in your Cube project:
Cube Cloud
In some cases you’ll need to allow connections from your Cube Cloud deployment
IP address to your database. You can copy the IP address from either the
Database Setup step in deployment creation, or from Settings →
Configuration in your deployment.
OIDC workload identity
Instead of a password or key pair, Cube Cloud deployments can authenticate to Snowflake with OIDC workload identity: a Snowflake External OAuth integration trusts Cube’s OIDC issuer, and the driver presents a short-lived Cube-minted JWT — no long-lived secrets to provision or rotate. Snowflake validates each connection’s token against your tenant’s public JWKS, maps the token’ssub claim to a Snowflake
user, and authorizes the session role through the token’s scp claim.
Start with the OIDC overview for the concepts (issuer,
token configs, custom claims, target env var) and to enable OIDC for your
tenant, then:
Create the token config
In Admin → OIDC, click Add Config and create a config with:
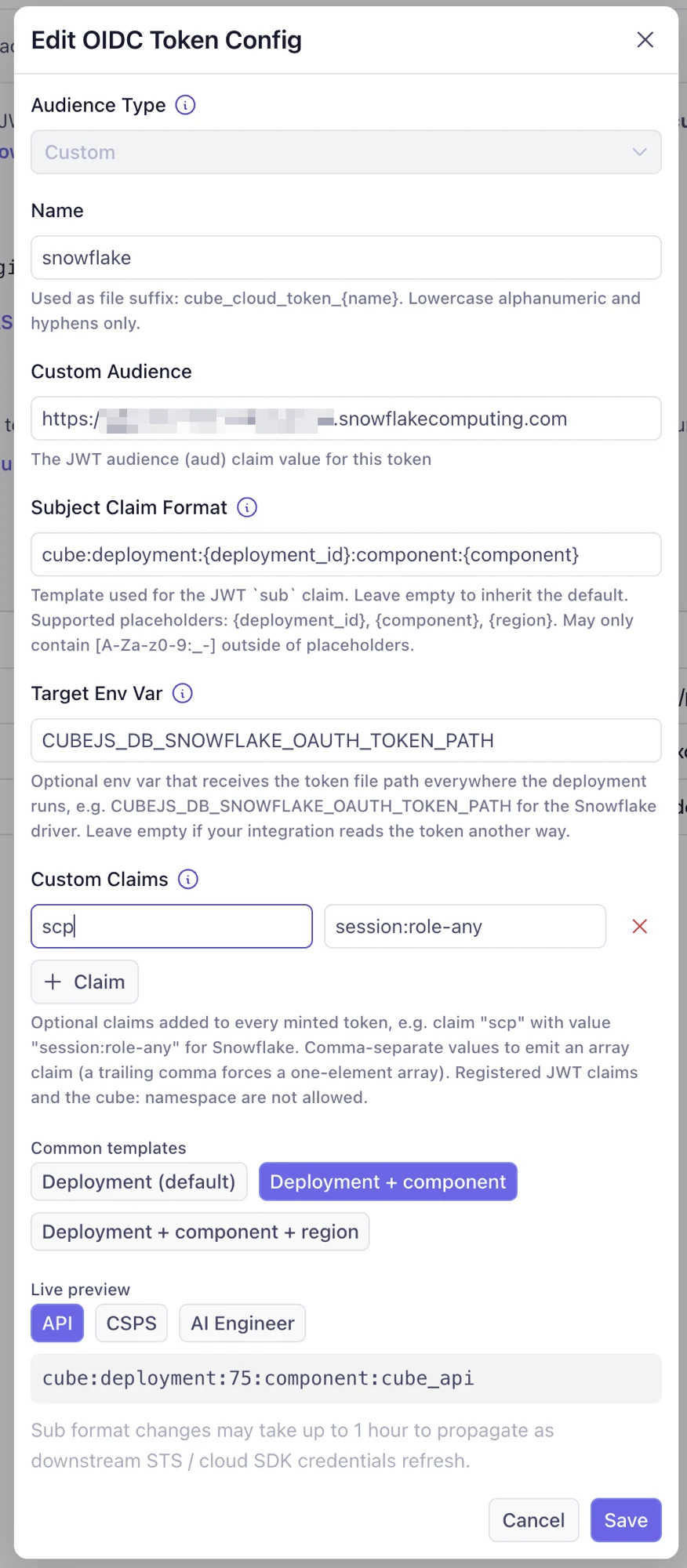
| Field | Value |
|---|---|
| Audience Type | Custom |
| Name | snowflake |
| Custom Audience | https://<account-identifier>.snowflakecomputing.com |
| Subject Claim Format | Keep the default, or pick a richer template — the rendered sub must match the Snowflake user’s LOGIN_NAME below |
| Custom Claims | Claim scp with value session:role-any |
| Target Env Var | CUBEJS_DB_SNOWFLAKE_OAUTH_TOKEN_PATH |
scp claim is the part that’s easy to miss: Snowflake grants
session roles exclusively through it — a token without scp
authenticates but fails role authorization. session:role-any lets the
driver request any role granted to the mapped user; to pin the role
inside the token instead, use session:role:<role-name> and
EXTERNAL_OAUTH_ANY_ROLE_MODE = 'DISABLE' below. The Target Env Var
is how the driver finds the token: Cube sets that env var to the token
file path in every execution context (deployed pods, dev mode, and test
connection each keep the file in a different place), so the path is
never written by hand.Create the External OAuth security integration
In a Snowflake worksheet, as The issuer and audience must match the token config exactly. Snowflake
fetches the JWKS from your tenant’s public endpoint, so no key material
changes hands.
ACCOUNTADMIN:Create the service user and role
The integration maps the token’s
sub claim to a Snowflake user via
LOGIN_NAME. With the default subject claim format the rendered sub
is cube:deployment:<deployment-id> — the deployment ID is the number
in your deployment’s console URL. If you chose a different template,
use the token-config dialog’s live preview to see the exact rendered
value.TYPE = SERVICE blocks password logins for this user entirely — it
can only authenticate through the federation.Configure the deployment
Set the
OAUTH authenticator and omit CUBEJS_DB_USER /
CUBEJS_DB_PASS:CUBEJS_DB_SNOWFLAKE_OAUTH_TOKEN_PATH is not set here — Cube
populates it automatically thanks to the Target Env Var from the
token config. The driver re-reads the file on every new connection, so
the broker’s automatic refresh is picked up without restarts.OAUTH_ACCESS_TOKEN as the authentication factor:
| Error | Cause |
|---|---|
Invalid OAuth access token | Issuer or audience mismatch between the token config and the security integration, or the JWKS URL is unreachable. |
The role … is not listed in the Access Token or was filtered | The scp custom claim is missing from the token config, or the role isn’t granted to the mapped user. |
User … not found / mapping errors | The rendered sub doesn’t match the Snowflake user’s LOGIN_NAME — compare against the dialog’s live preview. |
File … provided by CUBEJS_DB_SNOWFLAKE_OAUTH_TOKEN_PATH does not exist | The Target Env Var isn’t set on the token config (or a stale hand-written path is configured), or the deployment is still starting up. |
Environment Variables
| Environment Variable | Description | Possible Values | Required |
|---|---|---|---|
CUBEJS_DB_SNOWFLAKE_ACCOUNT | The Snowflake account identifier to use when connecting to the database | A valid Snowflake account ID | ✅ |
CUBEJS_DB_SNOWFLAKE_REGION | The Snowflake region to use when connecting to the database | A valid Snowflake region | ❌ |
CUBEJS_DB_SNOWFLAKE_WAREHOUSE | The Snowflake warehouse to use when connecting to the database | A valid Snowflake warehouse in the account | ✅ |
CUBEJS_DB_SNOWFLAKE_ROLE | The Snowflake role to use when connecting to the database | A valid Snowflake role in the account | ❌ |
CUBEJS_DB_SNOWFLAKE_CLIENT_SESSION_KEEP_ALIVE | If true, keep the Snowflake connection alive indefinitely | true, false | ❌ |
CUBEJS_DB_NAME | The name of the database to connect to | A valid database name | ✅ |
CUBEJS_DB_USER | The username used to connect to the database | A valid database username | ✅1 |
CUBEJS_DB_PASS | The password used to connect to the database | A valid database password | ✅1 |
CUBEJS_DB_SNOWFLAKE_AUTHENTICATOR | The type of authenticator to use with Snowflake. Use SNOWFLAKE with username/password, or SNOWFLAKE_JWT with key pairs. Defaults to SNOWFLAKE | SNOWFLAKE, SNOWFLAKE_JWT, OAUTH | ❌ |
CUBEJS_DB_SNOWFLAKE_PRIVATE_KEY | The content of the private RSA key | Content of the private RSA key (encrypted or not) | ❌ |
CUBEJS_DB_SNOWFLAKE_PRIVATE_KEY_PATH | The path to the private RSA key | A valid path to the private RSA key | ❌ |
CUBEJS_DB_SNOWFLAKE_PRIVATE_KEY_PASS | The password for the private RSA key. Only required for encrypted keys | A valid password for the encrypted private RSA key | ❌ |
CUBEJS_DB_SNOWFLAKE_OAUTH_TOKEN | The OAuth token | A valid OAuth token (string) | ❌ |
CUBEJS_DB_SNOWFLAKE_OAUTH_TOKEN_PATH | The path to the valid oauth toket file | A valid path for the oauth token file | ❌ |
CUBEJS_DB_SNOWFLAKE_HOST | Host address to which the driver should connect | A valid hostname | ❌ |
CUBEJS_DB_SNOWFLAKE_QUOTED_IDENTIFIERS_IGNORE_CASE | Whether or not quoted identifiers should be case insensitive. Default is false | true, false | ❌ |
CUBEJS_DB_MAX_POOL | The maximum number of concurrent database connections to pool. Default is 20 | A valid number | ❌ |
CUBEJS_CONCURRENCY | The number of concurrent queries to the data source | A valid number | ❌ |
SNOWFLAKE_JWT (key pair) or with OAUTH — including OIDC workload identity in Cube Cloud, where the driver reads a Cube-minted token from CUBEJS_DB_SNOWFLAKE_OAUTH_TOKEN_PATH.
Pre-Aggregation Feature Support
count_distinct_approx
Measures of typecount_distinct_approx can
be used in pre-aggregations when using Snowflake as a source database. To learn
more about Snowflake’s support for approximate aggregate functions, click
here.
Pre-Aggregation Build Strategies
To learn more about pre-aggregation build strategies, head
here.
| Feature | Works with read-only mode? | Is default? |
|---|---|---|
| Batching | ❌ | ✅ |
| Export Bucket | ❌ | ❌ |
Batching
No extra configuration is required to configure batching for Snowflake.Export Bucket
Snowflake supports using both AWS S3 and Google Cloud Storage for export bucket functionality.AWS S3
Ensure proper IAM privileges are configured for S3 bucket reads and writes, using either
storage integration or user credentials for Snowflake and either IAM roles/IRSA or user
credentials for Cube Store, with mixed configurations supported.
Google Cloud Storage
When using an export bucket, remember to assign the Storage Object Admin
role to your Google Cloud credentials (
CUBEJS_DB_EXPORT_GCS_CREDENTIALS).gcs_int from the example link) as you’ll need it to configure Cube.
Once the Snowflake integration is set up, configure Cube using the following:
Azure
To use Azure Blob Storage as an export bucket, follow the guide on using a Snowflake storage integration (Option 1). Take note of the integration name (azure_int from the example link)
as you’ll need it to configure Cube.
Retrieve the storage account access key from your Azure
account.
Once the Snowflake integration is set up, configure Cube using the following: